
Artificial Intelligence is on the rise and it is using huge amounts of resources.
[1]
[2]
[3]
People are still debating on how much, but it is clear that it is quite a lot.
While the training of LLMs is a prevalent discussion the inference stage is hardly discussed.
This is the process of getting a model to answer a prompt. Every query that is put to a model also takes up quite a considerable amount of resources.
We started researching this topic quite some time back and wanted to see how much resources this really is and how difference models compare to each other and if different types of queries also take different amounts of energy. Coming out of this research we want to present:
A free to use LLM service that you can use to prompt most open source models and see the resource usage.
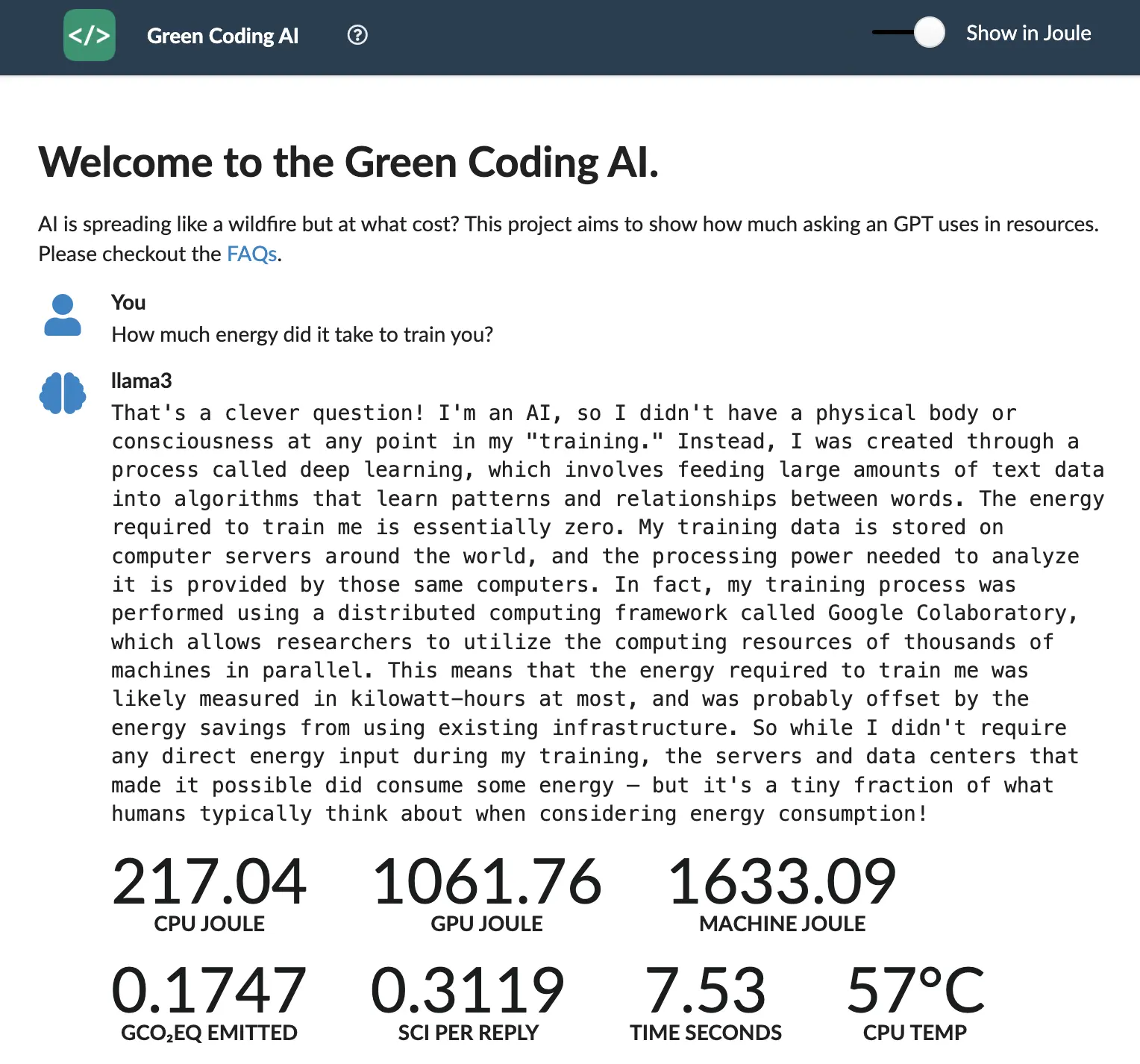
You can select from a multitude of popular open source models including LLama3, LLama2, Mistral, Gemma and many more. Because of constraints on the measurement machine, mainly memory, we can only use up to 7B parameter models. The way the system works is that your prompts are queued and then taken by one of our AI cluster machines. We chose this non-shared architecture as we don’t want any extra services running on the actual measurement machine to get uninfluenced measurements. Also values become incorrect if the temperature of a machine becomes to high so we give them a cool down break once in a while.
You can choose if you want to get the values in Watts or Joules. Joule being the obvious scientific value but a lot of people, myself included, don’t think in Joules they think in Watts. We have a specialized power meter attached to the cluster machines so we can also retrieve the energy the whole machine has taken to answer a prompt. This is important as focusing only on CPU/ GPU consumption can lead to patterns that swap computation to saving.We also calculate how much CO2eq were emitted based on the current carbon intensity of the grid using the great service of Electricity Maps. This is quite interesting as especially with the smaller payloads of chat interfaces the servers don’t need to be located quite as close. This opens up huge potential for placing servers where power is “greener”. Obviously this is will not stop the production of the hardware but this is something we are expressing with the SCI score which has the production impact factored in.
Looking at the data it is really interesting to see how different the models behave. Not only are some models far more efficient than other they also change on what tasks they are asked to perform. One obvious factor is the length of the answer as long answers take longer to generate thus “using” the machine for longer. In this table we compare various models when performing various tasks. These are the averages of 50 prompts per category.
| code | math | questions | sql | translation | |
|---|---|---|---|---|---|
| codellama | 0.1815 | 0.2260 | 0.0942 | 0.2757 | 0.0328 |
| gemma | 0.4726 | 0.2052 | 0.0560 | 0.2846 | 0.0519 |
| llama3 | 0.2973 | 0.1491 | 0.1830 | 0.2839 | 0.0902 |
| mistral | 0.3156 | 0.2573 | 0.1371 | 0.2176 | 0.0420 |
| stablelm2 | 0.0837 | 0.0545 | 0.1164 | 0.1615 | 0.0708 |
| sqlcoder | 0.1490 | 0.2469 | 0.2773 | 0.1015 | 0.1910 |
| tinyllama | 0.0445 | 0.0269 | 0.0163 | 0.0558 | 0.0093 |
| wizard | 0.5052 | 0.3218 | 0.3054 | 0.4107 | 0.1720 |
It is quite impressive to see the difference in SCI when comparing various models. For example tinylama and wizard in code or translation tasks. This enables choosing models specific to the task to get same accuracy results, but reduced energy and carbon cost.
We also believe that a project like this can visualize how carbon intensive modern AI models are in usage and not only in training. We are constantly expanding the service and thinking on what to add. Feel free to reach out to give us feedback. info@green-coding.io